Warning: package 'DT' was built under R version 4.4.3Anexos
Tabla de disponibilidad de las variables de cohesión
Datos
Cargando paquete requerido: pacmanWarning: package 'pacman' was built under R version 4.4.2Análisis de validación de constructos
Análisis factorial exploratorio
Factor seguridad
Se genera un subset de datos solamente con las variables que conforman el factor de seguridad para llevar a cabo el análisis.
elsoc_seg <- elsoc %>%
select(seguridad_sat, seguridad_perc, peleas_calle, asaltos, trafico_drogas)Las variables se convierten a numéricas.
elsoc_seg <- elsoc %>%
select(seguridad_sat, seguridad_perc, peleas_calle, asaltos, trafico_drogas) %>%
mutate(across(everything(), as.numeric))Se calcula la matriz de correlaciones
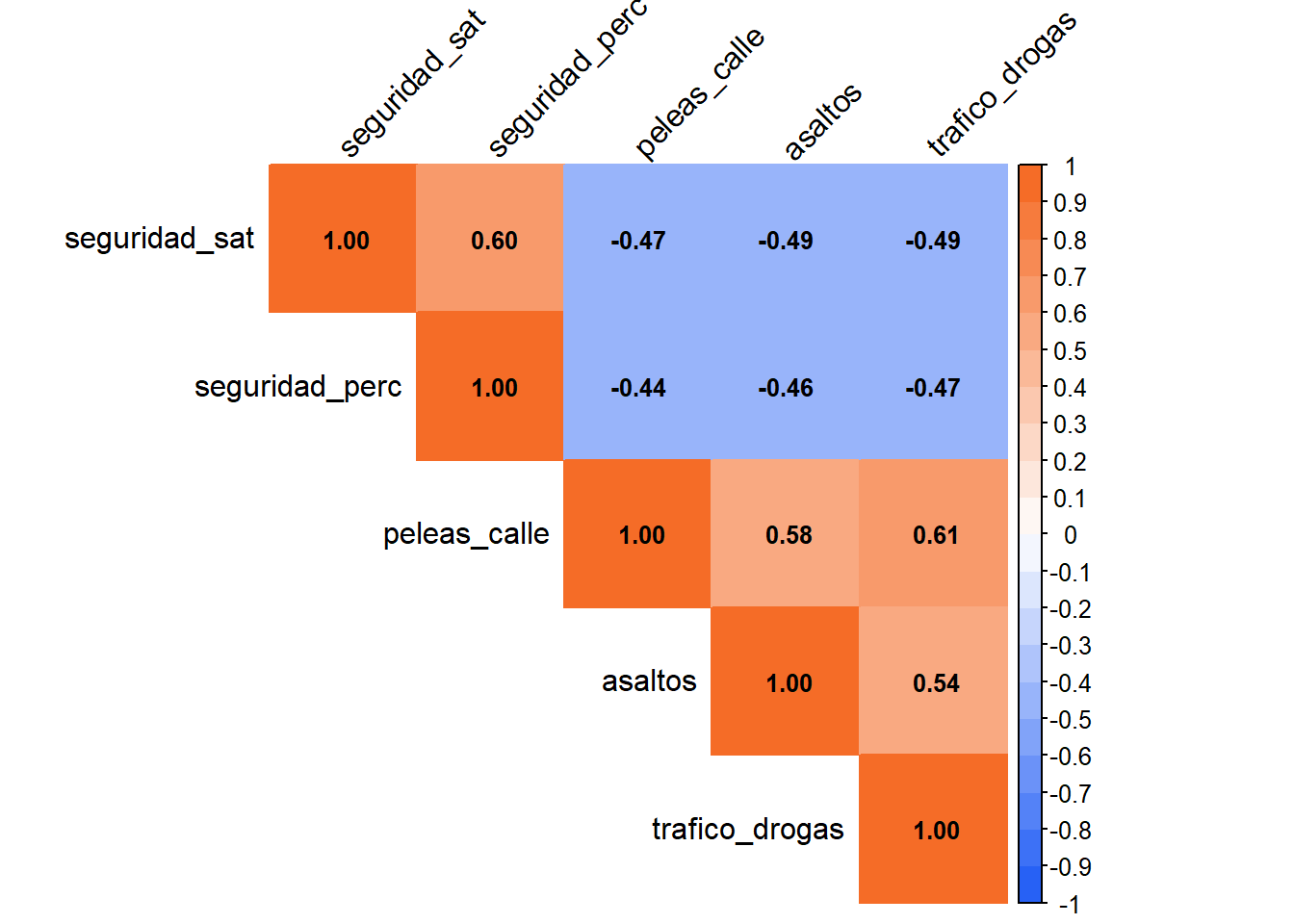
Kaiser-Meyer-Olkin factor adequacy
Call: KMO(r = corrseg)
Overall MSA = 0.83
MSA for each item =
seguridad_sat seguridad_perc peleas_calle asaltos trafico_drogas
0.82 0.82 0.82 0.86 0.84 $chisq
[1] 5182.035
$p.value
[1] 0
$df
[1] 10Ya con la matriz de correlaciones lista, pasamos a realizar el EFA
Parallel analysis suggests that the number of factors = 2 and the number of components = NA | Factor 1 | Factor 2 | Communality | |
|---|---|---|---|
| seguridad_sat | -0.35 | 0.72 | 0.63 |
| seguridad_perc | -0.32 | 0.69 | 0.57 |
| peleas_calle | 0.78 | -0.27 | 0.69 |
| asaltos | 0.60 | -0.39 | 0.51 |
| trafico_drogas | 0.65 | -0.38 | 0.56 |
| Total Communalities | 2.97 | ||
| Cronbach's α | 0.80 | 0.75 | |
En Table 1 se puede apreciar que el factorial exploratorio reconoce la existencia de dos factores latentes. Uno de ellos puede comprenderse como seguridad subjetiva, el cual integra los indicadores de satisfacción de seguridad y percepción de seguridad. Ambos indicadores poseen cargas factoriales altas, así como un alfa de Cronbach aceptable, por lo que es un factor consistente. El segundo factor contiene los indicadores de frecuencia de conflictos en el barrio, por lo que pueden agruparse bajo el factor de seguridad objetiva. El factor explica en buena medida as cargas factoriales de los tres indicadores en tanto rondan entre .6 y .8. Su alfa de Cronbach refleja una buena consistencia entre los indicadores de seguridad objetiva.
Factor de calidad de vida en el vecindario
Subset con los indicadores necesarios
Las variables se convierten a numéricas
Se calcula la matriz de correlaciones
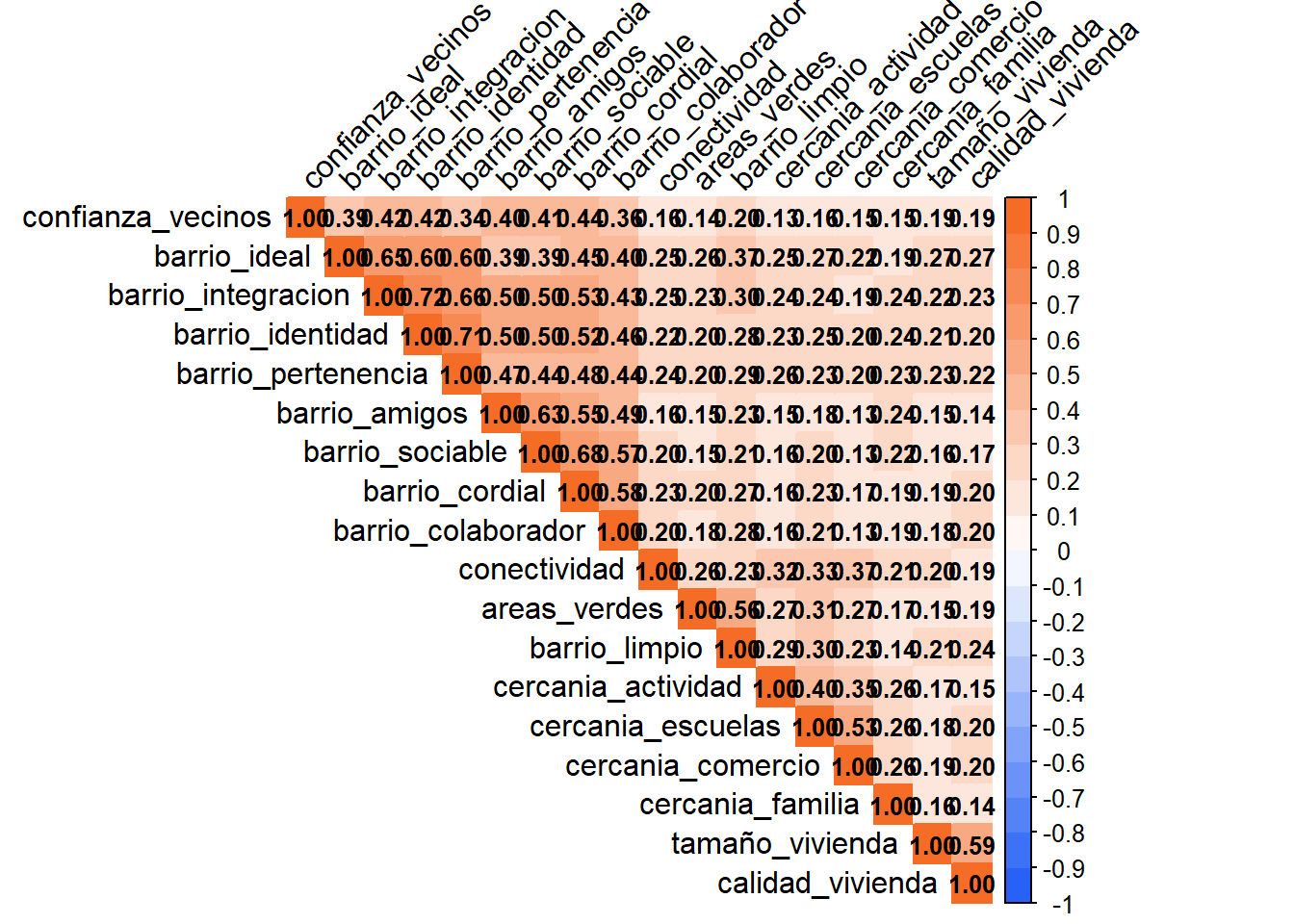
Kaiser-Meyer-Olkin factor adequacy
Call: KMO(r = corrbarrio)
Overall MSA = 0.9
MSA for each item =
confianza_vecinos barrio_ideal barrio_integracion barrio_identidad
0.96 0.94 0.92 0.92
barrio_pertenencia barrio_amigos barrio_sociable barrio_cordial
0.92 0.93 0.89 0.92
barrio_colaborador conectividad areas_verdes barrio_limpio
0.95 0.93 0.81 0.84
cercania_actividad cercania_escuelas cercania_comercio cercania_familia
0.91 0.86 0.84 0.94
tamaño_vivienda calidad_vivienda
0.76 0.76 $chisq
[1] 19599.6
$p.value
[1] 0
$df
[1] 153Parallel analysis suggests that the number of factors = 5 and the number of components = NA | Factor 1 | Factor 2 | Factor 3 | Factor 4 | Factor 5 | Communality | |
|---|---|---|---|---|---|---|
| confianza_vecinos | 0.43 | 0.29 | 0.11 | 0.13 | 0.07 | 0.30 |
| barrio_ideal | 0.29 | 0.61 | 0.20 | 0.17 | 0.21 | 0.57 |
| barrio_integracion | 0.40 | 0.70 | 0.18 | 0.10 | 0.11 | 0.70 |
| barrio_identidad | 0.40 | 0.73 | 0.18 | 0.07 | 0.06 | 0.73 |
| barrio_pertenencia | 0.34 | 0.70 | 0.18 | 0.10 | 0.09 | 0.65 |
| barrio_amigos | 0.66 | 0.29 | 0.11 | 0.04 | 0.07 | 0.53 |
| barrio_sociable | 0.82 | 0.19 | 0.12 | 0.05 | 0.03 | 0.73 |
| barrio_cordial | 0.73 | 0.26 | 0.15 | 0.09 | 0.11 | 0.64 |
| barrio_colaborador | 0.62 | 0.23 | 0.12 | 0.09 | 0.14 | 0.48 |
| conectividad | 0.13 | 0.12 | 0.46 | 0.12 | 0.12 | 0.27 |
| areas_verdes | 0.09 | 0.09 | 0.30 | 0.07 | 0.57 | 0.44 |
| barrio_limpio | 0.15 | 0.16 | 0.20 | 0.12 | 0.81 | 0.76 |
| cercania_actividad | 0.06 | 0.15 | 0.50 | 0.06 | 0.18 | 0.31 |
| cercania_escuelas | 0.11 | 0.08 | 0.68 | 0.07 | 0.16 | 0.51 |
| cercania_comercio | 0.03 | 0.06 | 0.71 | 0.10 | 0.08 | 0.53 |
| cercania_familia | 0.18 | 0.13 | 0.35 | 0.08 | 0.02 | 0.18 |
| tamaño_vivienda | 0.09 | 0.12 | 0.16 | 0.74 | 0.06 | 0.60 |
| calidad_vivienda | 0.10 | 0.10 | 0.16 | 0.72 | 0.11 | 0.58 |
| Total Communalities | 9.53 | |||||
| Cronbach's α | 0.83 | 0.88 | 0.71 | 0.74 | 0.72 | |
En Table 2 se observan cinco factores. El factor con consistencia interna más alta (0.83) contiene las variables relacionadas al agrado y/o comodidad que sienten las personas respecto a su barrio, en donde solamente la variable confianza en vecinos se escapa de esta tónica. El segundo factor agrupa indicadores que dan cuenta del sentido de pertenencia de la persona en el barrio, aludiendo a aspectos identitarios. El tercer factor consiste, en general, en la proximidad física del barrio respecto a servicios. El cuarto factor mide la percepción de la persona respecto a su vivienda desde una dimensión física de espacio y calidad material. Por último, el quinto factor considera dos variables que pueden ser asociadas a las áreas verdes y limpias del barrio. Todos los factores poseen una buena consistencia interna.
Factor redes sociales (ola 5)
Seleccionamos las variables a utilizar
Pasamos las variables a numéricas
Estimamos la matriz de correlaciones
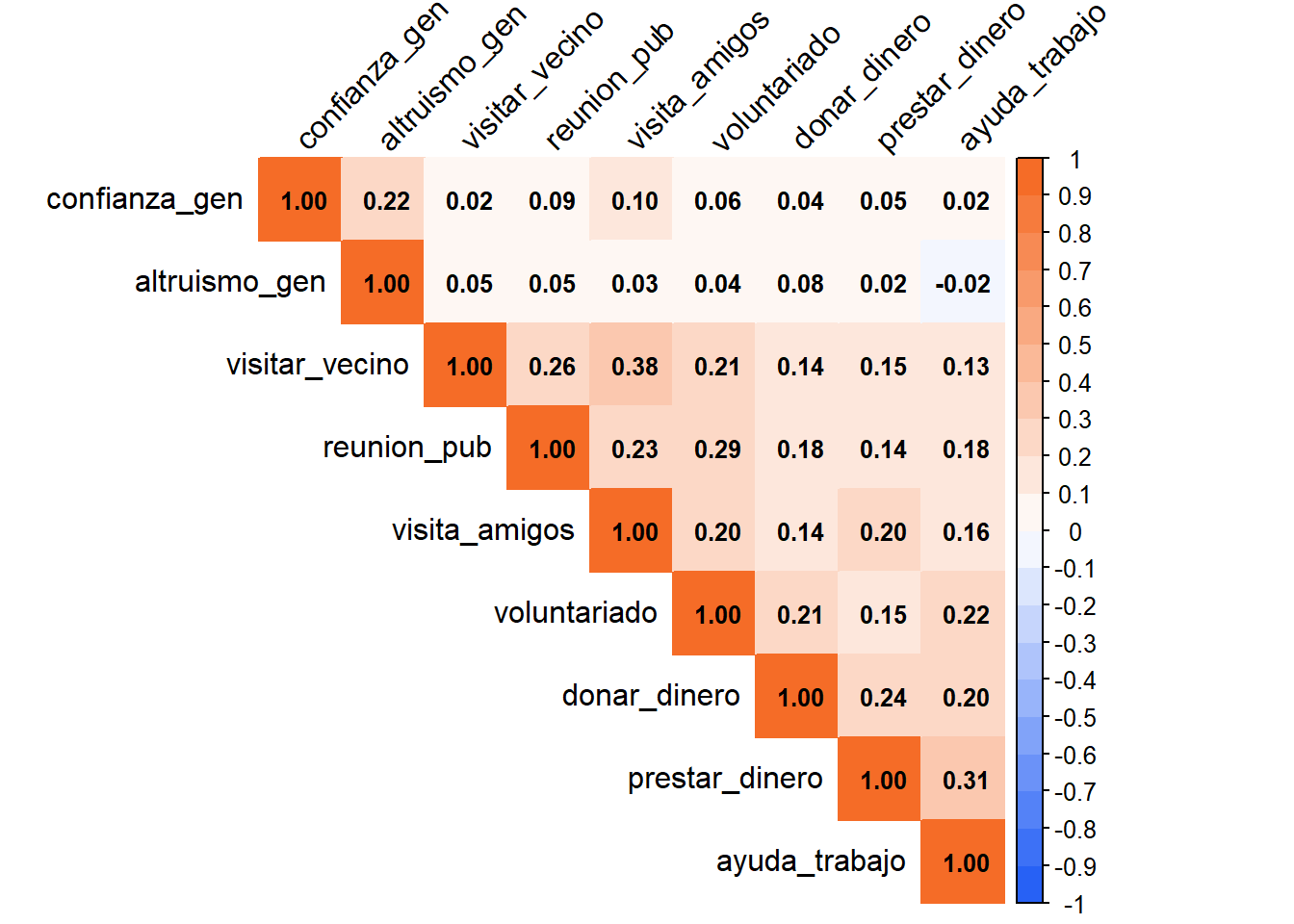
Kaiser-Meyer-Olkin factor adequacy
Call: KMO(r = corredes)
Overall MSA = 0.72
MSA for each item =
confianza_gen altruismo_gen visitar_vecino reunion_pub visita_amigos
0.55 0.53 0.70 0.77 0.71
voluntariado donar_dinero prestar_dinero ayuda_trabajo
0.77 0.78 0.72 0.73 $chisq
[1] 2114.983
$p.value
[1] 0
$df
[1] 36Parallel analysis suggests that the number of factors = 4 and the number of components = NA | Factor 1 | Factor 2 | Factor 3 | Factor 4 | Communality | |
|---|---|---|---|---|---|
| confianza_gen | 1.00 | 0.04 | 0.00 | -0.00 | 0.99 |
| altruismo_gen | 0.22 | 0.00 | 0.04 | 0.05 | 0.05 |
| visitar_vecino | 0.02 | 0.07 | 0.66 | 0.19 | 0.47 |
| reunion_pub | 0.09 | 0.11 | 0.26 | 0.42 | 0.27 |
| visita_amigos | 0.10 | 0.17 | 0.51 | 0.16 | 0.32 |
| voluntariado | 0.06 | 0.13 | 0.15 | 0.55 | 0.35 |
| donar_dinero | 0.03 | 0.29 | 0.10 | 0.29 | 0.18 |
| prestar_dinero | 0.03 | 0.71 | 0.13 | 0.06 | 0.53 |
| ayuda_trabajo | 0.00 | 0.40 | 0.08 | 0.28 | 0.24 |
| Total Communalities | 3.40 | ||||
| Cronbach's α | 0.34 | 0.50 | 0.55 | 0.45 | |
Table 3 refleja que, después del EFA, se sugiere la existencia de 4 factores. El primero de ellos agrupa dos variables que pueden ser relacionadas a la confianza interpersonal. El segundo factor contiene variables que encuentran sentido dentro de la ayuda económica que puede brindarle una persona a otra, ya sea de una manera directa como donar y/o prestar dinero, o de modo indirecto como lo es ayudar a encontrar trabajo a otro. El factor aborda dos variables que refieren a dar y recibir una visita a personas cercanas, tales como vecinos y amigos, respectivamente. El cuarto y último factor agrupa dos variables, una sobre asistencia reuniones públicas y otra sobre participación en voluntariados, actitudes que podrían entenderse como prosociales.
Análisis factorial confirmatorio
Factor seguridad
Especificamos el modelo tomando en cuenta la propuesta teórica del documento.
Se estima el modelo
Visualizamos los resultados
lavaan 0.6-18 ended normally after 18 iterations
Estimator DWLS
Optimization method NLMINB
Number of model parameters 26
Used Total
Number of observations 2403 2730
Model Test User Model:
Standard Scaled
Test Statistic 10.109 27.370
Degrees of freedom 4 4
P-value (Chi-square) 0.039 0.000
Scaling correction factor 0.372
Shift parameter 0.220
simple second-order correction
Model Test Baseline Model:
Test statistic 18024.644 11961.968
Degrees of freedom 10 10
P-value 0.000 0.000
Scaling correction factor 1.507
User Model versus Baseline Model:
Comparative Fit Index (CFI) 1.000 0.998
Tucker-Lewis Index (TLI) 0.999 0.995
Robust Comparative Fit Index (CFI) 0.996
Robust Tucker-Lewis Index (TLI) 0.989
Root Mean Square Error of Approximation:
RMSEA 0.025 0.049
90 Percent confidence interval - lower 0.005 0.033
90 Percent confidence interval - upper 0.045 0.068
P-value H_0: RMSEA <= 0.050 0.982 0.487
P-value H_0: RMSEA >= 0.080 0.000 0.002
Robust RMSEA 0.052
90 Percent confidence interval - lower 0.033
90 Percent confidence interval - upper 0.072
P-value H_0: Robust RMSEA <= 0.050 0.402
P-value H_0: Robust RMSEA >= 0.080 0.011
Standardized Root Mean Square Residual:
SRMR 0.012 0.012
Parameter Estimates:
Parameterization Delta
Standard errors Robust.sem
Information Expected
Information saturated (h1) model Unstructured
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
subjetiva =~
seguridad_perc 1.000 0.786 0.786
seguridad_sat 1.051 0.026 40.455 0.000 0.826 0.826
objetiva =~
peleas_calle 1.000 0.842 0.842
asaltos 0.933 0.016 56.583 0.000 0.785 0.785
trafico_drogas 0.967 0.017 58.072 0.000 0.814 0.814
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
subjetiva ~~
objetiva -0.533 0.015 -36.666 0.000 -0.806 -0.806
Thresholds:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
segurdd_prc|t1 -1.679 0.044 -38.053 0.000 -1.679 -1.679
segurdd_prc|t2 -0.766 0.028 -26.885 0.000 -0.766 -0.766
segurdd_prc|t3 -0.190 0.026 -7.399 0.000 -0.190 -0.190
segurdd_prc|t4 1.257 0.034 36.476 0.000 1.257 1.257
seguridd_st|t1 -1.603 0.042 -38.216 0.000 -1.603 -1.603
seguridd_st|t2 -0.569 0.027 -20.972 0.000 -0.569 -0.569
seguridd_st|t3 -0.099 0.026 -3.854 0.000 -0.099 -0.099
seguridd_st|t4 1.400 0.037 37.707 0.000 1.400 1.400
peleas_call|t1 -0.059 0.026 -2.305 0.021 -0.059 -0.059
peleas_call|t2 0.632 0.028 22.953 0.000 0.632 0.632
peleas_call|t3 1.176 0.033 35.460 0.000 1.176 1.176
peleas_call|t4 1.846 0.050 37.072 0.000 1.846 1.846
asaltos|t1 -0.453 0.027 -17.048 0.000 -0.453 -0.453
asaltos|t2 0.299 0.026 11.506 0.000 0.299 0.299
asaltos|t3 0.973 0.031 31.910 0.000 0.973 0.973
asaltos|t4 1.791 0.048 37.482 0.000 1.791 1.791
trafic_drgs|t1 -0.264 0.026 -10.207 0.000 -0.264 -0.264
trafic_drgs|t2 0.163 0.026 6.340 0.000 0.163 0.163
trafic_drgs|t3 0.564 0.027 20.813 0.000 0.564 0.564
trafic_drgs|t4 1.176 0.033 35.460 0.000 1.176 1.176
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.seguridad_perc 0.382 0.382 0.382
.seguridad_sat 0.317 0.317 0.317
.peleas_calle 0.292 0.292 0.292
.asaltos 0.384 0.384 0.384
.trafico_drogas 0.338 0.338 0.338
subjetiva 0.618 0.020 31.175 0.000 1.000 1.000
objetiva 0.708 0.017 41.904 0.000 1.000 1.000Cargas factoriales estandarizadas
lhs rhs est.std
1 subjetiva seguridad_perc 0.786
2 subjetiva seguridad_sat 0.826
3 objetiva peleas_calle 0.842
4 objetiva asaltos 0.785
5 objetiva trafico_drogas 0.814En este modelo todas las cargas factoriales estandarizadas son altas, donde los cinco indicadores oscilan entre el 0.7 y 0.8. Todos los indicadores son explicados en buena medida por su factor latente respectivo.
Factor vinculación territorial
Después de haber visto los EFA, sumado a la idea de realizar una propuesta minimalista de cohesión social, es que se propone modificar la subdimensión de “calidad de vida en el vecindario” y llamarla “vinculación territorial”, la cual estaría compuesta por un factor de sentido de pertenencia territorial y otro de satisfacción con el barrio.
Estimación del modelo
lavaan 0.6-18 ended normally after 23 iterations
Estimator DWLS
Optimization method NLMINB
Number of model parameters 41
Used Total
Number of observations 2525 2730
Model Test User Model:
Standard Scaled
Test Statistic 109.585 259.088
Degrees of freedom 19 19
P-value (Chi-square) 0.000 0.000
Scaling correction factor 0.428
Shift parameter 3.101
simple second-order correction
Model Test Baseline Model:
Test statistic 96965.694 40795.676
Degrees of freedom 28 28
P-value 0.000 0.000
Scaling correction factor 2.378
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.999 0.994
Tucker-Lewis Index (TLI) 0.999 0.991
Robust Comparative Fit Index (CFI) 0.980
Robust Tucker-Lewis Index (TLI) 0.971
Root Mean Square Error of Approximation:
RMSEA 0.043 0.071
90 Percent confidence interval - lower 0.036 0.063
90 Percent confidence interval - upper 0.052 0.079
P-value H_0: RMSEA <= 0.050 0.907 0.000
P-value H_0: RMSEA >= 0.080 0.000 0.025
Robust RMSEA 0.079
90 Percent confidence interval - lower 0.072
90 Percent confidence interval - upper 0.088
P-value H_0: Robust RMSEA <= 0.050 0.000
P-value H_0: Robust RMSEA >= 0.080 0.463
Standardized Root Mean Square Residual:
SRMR 0.021 0.021
Parameter Estimates:
Parameterization Delta
Standard errors Robust.sem
Information Expected
Information saturated (h1) model Unstructured
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
pertenencia =~
barrio_ideal 1.000 0.780 0.780
barrio_intgrcn 1.138 0.013 86.330 0.000 0.887 0.887
barrio_identdd 1.149 0.013 88.538 0.000 0.896 0.896
barrio_pertnnc 1.105 0.013 85.890 0.000 0.861 0.861
satisfaccion =~
barrio_amigos 1.000 0.791 0.791
barrio_sociabl 1.102 0.014 80.348 0.000 0.872 0.872
barrio_cordial 1.118 0.013 82.957 0.000 0.885 0.885
barrio_colbrdr 0.962 0.014 67.989 0.000 0.761 0.761
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
pertenencia ~~
satisfaccion 0.472 0.011 42.483 0.000 0.765 0.765
Thresholds:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
barrio_idel|t1 -1.982 0.054 -36.608 0.000 -1.982 -1.982
barrio_idel|t2 -0.999 0.030 -33.260 0.000 -0.999 -0.999
barrio_idel|t3 -0.572 0.026 -21.604 0.000 -0.572 -0.572
barrio_idel|t4 1.023 0.030 33.728 0.000 1.023 1.023
barr_ntgrcn|t1 -2.042 0.057 -35.847 0.000 -2.042 -2.042
barr_ntgrcn|t2 -1.138 0.032 -35.784 0.000 -1.138 -1.138
barr_ntgrcn|t3 -0.642 0.027 -23.844 0.000 -0.642 -0.642
barr_ntgrcn|t4 1.048 0.031 34.221 0.000 1.048 1.048
barri_dntdd|t1 -2.050 0.057 -35.739 0.000 -2.050 -2.050
barri_dntdd|t2 -1.001 0.030 -33.293 0.000 -1.001 -1.001
barri_dntdd|t3 -0.479 0.026 -18.405 0.000 -0.479 -0.479
barri_dntdd|t4 1.079 0.031 34.799 0.000 1.079 1.079
barr_prtnnc|t1 -2.110 0.060 -34.885 0.000 -2.110 -2.110
barr_prtnnc|t2 -1.090 0.031 -34.988 0.000 -1.090 -1.090
barr_prtnnc|t3 -0.609 0.027 -22.804 0.000 -0.609 -0.609
barr_prtnnc|t4 1.003 0.030 33.327 0.000 1.003 1.003
barrio_amgs|t1 -1.868 0.049 -37.809 0.000 -1.868 -1.868
barrio_amgs|t2 -0.790 0.028 -28.232 0.000 -0.790 -0.790
barrio_amgs|t3 -0.121 0.025 -4.834 0.000 -0.121 -0.121
barrio_amgs|t4 1.397 0.036 38.634 0.000 1.397 1.397
barrio_scbl|t1 -2.119 0.061 -34.747 0.000 -2.119 -2.119
barrio_scbl|t2 -1.058 0.031 -34.415 0.000 -1.058 -1.058
barrio_scbl|t3 -0.412 0.026 -16.009 0.000 -0.412 -0.412
barrio_scbl|t4 1.310 0.035 37.951 0.000 1.310 1.310
barrio_crdl|t1 -2.148 0.063 -34.307 0.000 -2.148 -2.148
barrio_crdl|t2 -1.205 0.033 -36.757 0.000 -1.205 -1.205
barrio_crdl|t3 -0.578 0.027 -21.798 0.000 -0.578 -0.578
barrio_crdl|t4 1.254 0.034 37.360 0.000 1.254 1.254
barr_clbrdr|t1 -1.989 0.054 -36.522 0.000 -1.989 -1.989
barr_clbrdr|t2 -1.058 0.031 -34.415 0.000 -1.058 -1.058
barr_clbrdr|t3 -0.388 0.026 -15.141 0.000 -0.388 -0.388
barr_clbrdr|t4 1.203 0.033 36.729 0.000 1.203 1.203
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.barrio_ideal 0.392 0.392 0.392
.barrio_intgrcn 0.213 0.213 0.213
.barrio_identdd 0.197 0.197 0.197
.barrio_pertnnc 0.258 0.258 0.258
.barrio_amigos 0.374 0.374 0.374
.barrio_sociabl 0.240 0.240 0.240
.barrio_cordial 0.217 0.217 0.217
.barrio_colbrdr 0.421 0.421 0.421
pertenencia 0.608 0.013 45.550 0.000 1.000 1.000
satisfaccion 0.626 0.014 45.405 0.000 1.000 1.000Cargas factoriales estandarizadas
lhs rhs est.std
1 pertenencia barrio_ideal 0.780
2 pertenencia barrio_integracion 0.887
3 pertenencia barrio_identidad 0.896
4 pertenencia barrio_pertenencia 0.861
5 satisfaccion barrio_amigos 0.791
6 satisfaccion barrio_sociable 0.872
7 satisfaccion barrio_cordial 0.885
8 satisfaccion barrio_colaborador 0.761Todas las cargas factoriales son altas, rondando entre en 0.7 y 0.8, por lo que ambos factores estarían explicando consistentemente sus indicadores correspondientes.
Factor redes sociales
A partir del EFA y la idea de minimalizar la propuesta, se decide plantear un modelo con tres factores: confianza interpersonal, comportamiento prosocial y apoyo económico. Se reduce la cantidad de indicadores de 10 a 6, dos pertenecientes a cada factor. Si bien, el factor de visita a personas cercanas tenía buena consistencia interna, se descartó de la propuesta por falta de relevancia teórica con lo que respecta a la cohesión social.
Warning: lavaan->lav_object_post_check():
some estimated ov variances are negativeWarning: lavaan->lav_object_post_check():
some estimated ov variances are negative
Warning: lavaan->lav_object_post_check():
some estimated ov variances are negativelavaan 0.6-18 ended normally after 40 iterations
Estimator DWLS
Optimization method NLMINB
Number of model parameters 21
Used Total
Number of observations 2723 2740
Model Test User Model:
Standard Scaled
Test Statistic 8.326 11.873
Degrees of freedom 6 6
P-value (Chi-square) 0.215 0.065
Scaling correction factor 0.711
Shift parameter 0.156
simple second-order correction
Model Test Baseline Model:
Test statistic 1223.087 1103.315
Degrees of freedom 15 15
P-value 0.000 0.000
Scaling correction factor 1.110
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.998 0.995
Tucker-Lewis Index (TLI) 0.995 0.987
Robust Comparative Fit Index (CFI) 0.993
Robust Tucker-Lewis Index (TLI) 0.981
Root Mean Square Error of Approximation:
RMSEA 0.012 0.019
90 Percent confidence interval - lower 0.000 0.000
90 Percent confidence interval - upper 0.029 0.035
P-value H_0: RMSEA <= 0.050 1.000 1.000
P-value H_0: RMSEA >= 0.080 0.000 0.000
Robust RMSEA 0.031
90 Percent confidence interval - lower 0.000
90 Percent confidence interval - upper 0.067
P-value H_0: Robust RMSEA <= 0.050 0.774
P-value H_0: Robust RMSEA >= 0.080 0.008
Standardized Root Mean Square Residual:
SRMR 0.022 0.022
Parameter Estimates:
Parameterization Delta
Standard errors Robust.sem
Information Expected
Information saturated (h1) model Unstructured
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
confianza_inter =~
confianza_gen 1.000 1.013 1.013
altruismo_gen 0.405 0.170 2.377 0.017 0.411 0.411
prosocial =~
reunion_pub 1.000 0.614 0.614
voluntariado 1.192 0.114 10.466 0.000 0.732 0.732
economica =~
prestar_dinero 1.000 0.563 0.563
ayuda_trabajo 1.301 0.132 9.854 0.000 0.733 0.733
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
confianza_inter ~~
prosocial 0.145 0.032 4.496 0.000 0.233 0.233
economica 0.047 0.027 1.789 0.074 0.083 0.083
prosocial ~~
economica 0.215 0.024 8.889 0.000 0.623 0.623
Thresholds:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
confianz_gn|t1 1.286 0.033 39.166 0.000 1.286 1.286
confianz_gn|t2 1.440 0.036 40.367 0.000 1.440 1.440
altruism_gn|t1 0.672 0.026 25.742 0.000 0.672 0.672
altruism_gn|t2 0.902 0.028 32.281 0.000 0.902 0.902
reunion_pub|t1 0.662 0.026 25.411 0.000 0.662 0.662
reunion_pub|t2 1.233 0.032 38.546 0.000 1.233 1.233
voluntariad|t1 0.745 0.027 28.005 0.000 0.745 0.745
voluntariad|t2 1.082 0.030 36.192 0.000 1.082 1.082
prestar_dnr|t1 -0.556 0.025 -21.880 0.000 -0.556 -0.556
prestar_dnr|t2 0.015 0.024 0.632 0.527 0.015 0.015
ayuda_trabj|t1 -0.214 0.024 -8.826 0.000 -0.214 -0.214
ayuda_trabj|t2 0.481 0.025 19.211 0.000 0.481 0.481
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.confianza_gen -0.027 -0.027 -0.027
.altruismo_gen 0.831 0.831 0.831
.reunion_pub 0.623 0.623 0.623
.voluntariado 0.465 0.465 0.465
.prestar_dinero 0.682 0.682 0.682
.ayuda_trabajo 0.463 0.463 0.463
confianza_intr 1.027 0.433 2.371 0.018 1.000 1.000
prosocial 0.377 0.044 8.562 0.000 1.000 1.000
economica 0.318 0.038 8.325 0.000 1.000 1.000El modelo tiene buenos índices de ajuste, por lo que a nivel general su estructura es factible. Sin embargo, en confianza interpersonal, el indicador de confianza social generalizada posee una carga factorial muy alta (sobre 1) en comparación de altruismo social generalizado (.41), por lo que se interpreta que confianza generalizada podría ser un factor por sí solo, prescindiendo del otro indicador. Aun así, esto puede ser solucionado con una restricción de igualdad en la especificación del modelo, lo que ayudaría a preservar su estabilidad y justificación para ser parte la propuesta.
Cohesión y seguridad
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.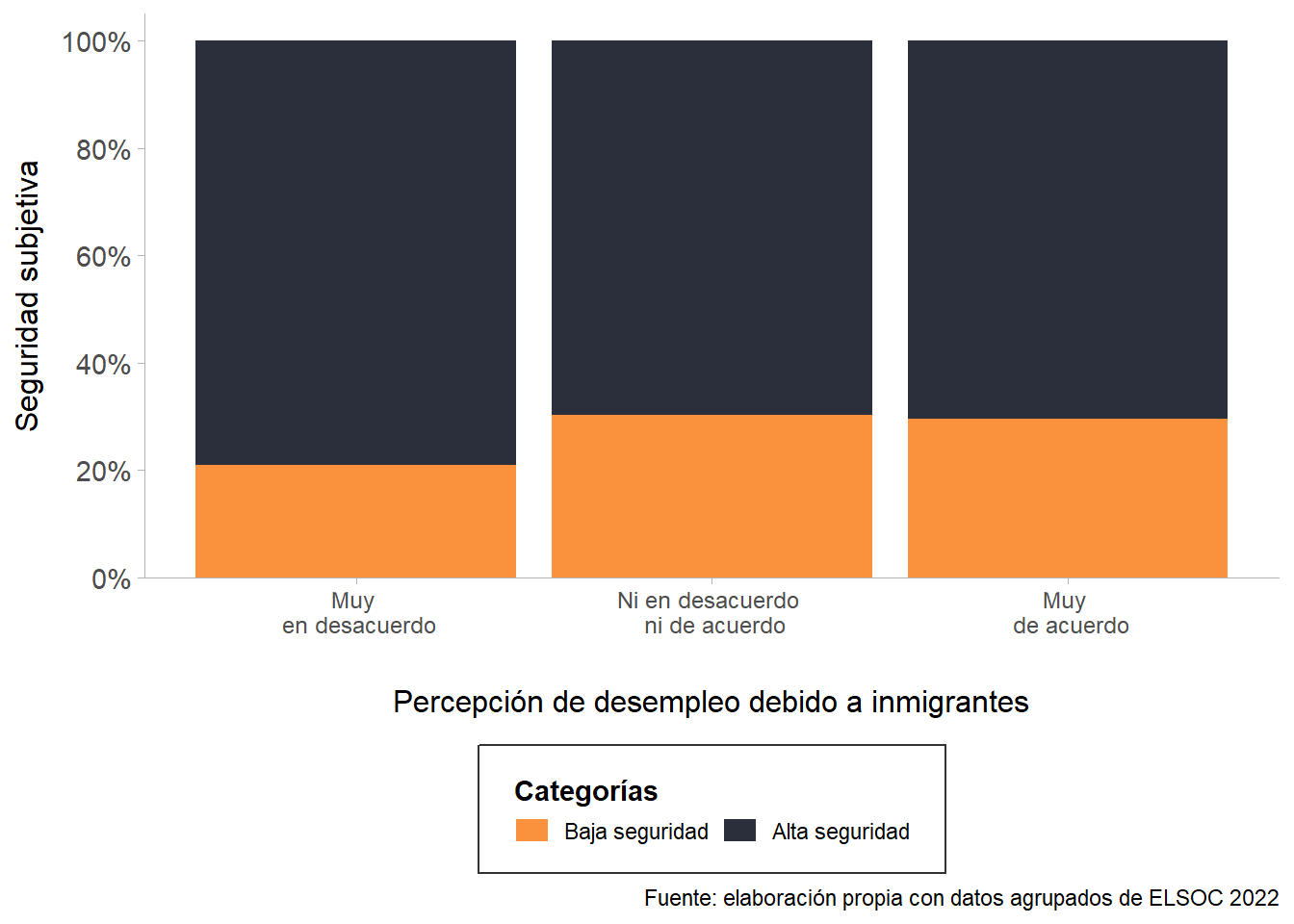
En la Figure 5 se visualiza la asociación entre la percepción de aumento de desempleo a causa de inmigrantes (eje x), y el índice de seguridad subjetiva (eje y), el cual fue construido mediante el promedio calculado de dos indicadores: satisfacción de seguridad en el barrio y percepción de seguridad barrial (si le interesa profundizar en cómo se construyó este y los demás índices, vaya al anexo).
Se puede apreciar que la cantidad de personas que percibe una seguridad baja aumenta en la medida que se está más de acuerdo con que los inmigrantes causan desempleo en el país. Esto se nota en la consistencia en las categorías “Ni en desacuerdo ni de acuerdo” y “Muy de acuerdo” respecto a la concentración de respuestas, superando notoriamente la poca seguridad de quienes no creen que la inmigración incide en la empleabilidad. Por tanto, se refleja una correlación negativa entre la sensación de seguridad y la carencia de empleos debido a extranjeros.
En la Figure 6 se grafica la relación entre la percepción de pérdida de identidad del país a causa de inmigrantes y el índice de seguridad objetiva, el cual fue medido a partir de la frecuencia de peleas callejeras, asaltos y tráfico de drogas en el barrio del encuestado.
Asimismo, se puede apreciar que las cantidad de personas que viven niveles bajos de seguridad aumenta progresivamente a medida que se está más de acuerdo con que los inmigrantes le restan identidad al país. Por tanto, mientras menos seguras están las personas, se está más convencido de que los inmigrantes erosionan la identidad de Chile.
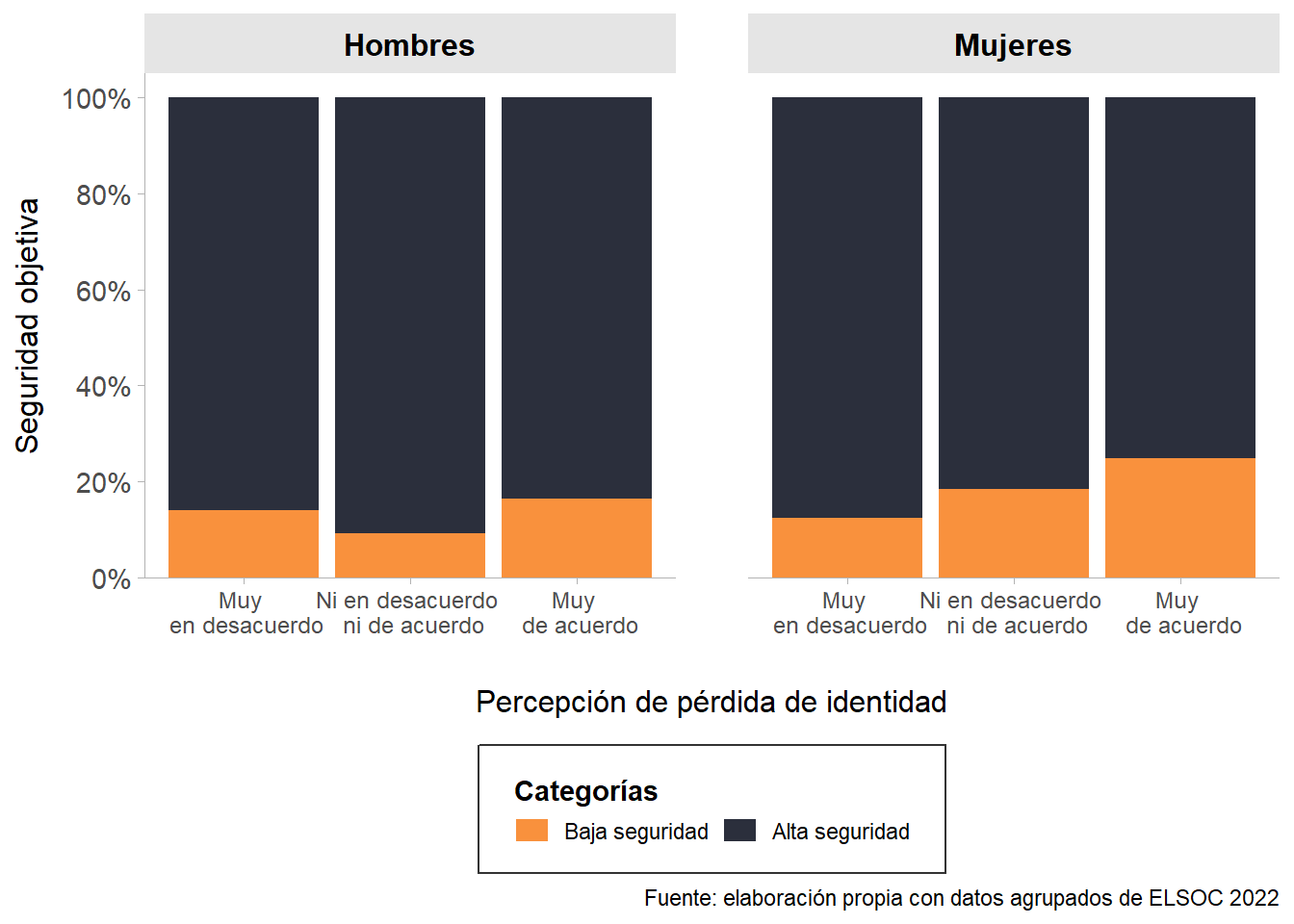
La Figure 7 refleja la asociación entre seguridad objetiva y percepción de pérdida de identidad del país a causa de los inmigrantes, lo cual está graficado por hombres y mujeres. Se puede observar que, en el caso de los hombres, las categorías más polarizadas concentran la mayoría de las respuestas, por lo que no hay un patrón muy claro. En cambio, a medida que las mujeres viven en entornos menos seguros, están más de acuerdo con que el país pierde identidad a causa de los inmigrantes.
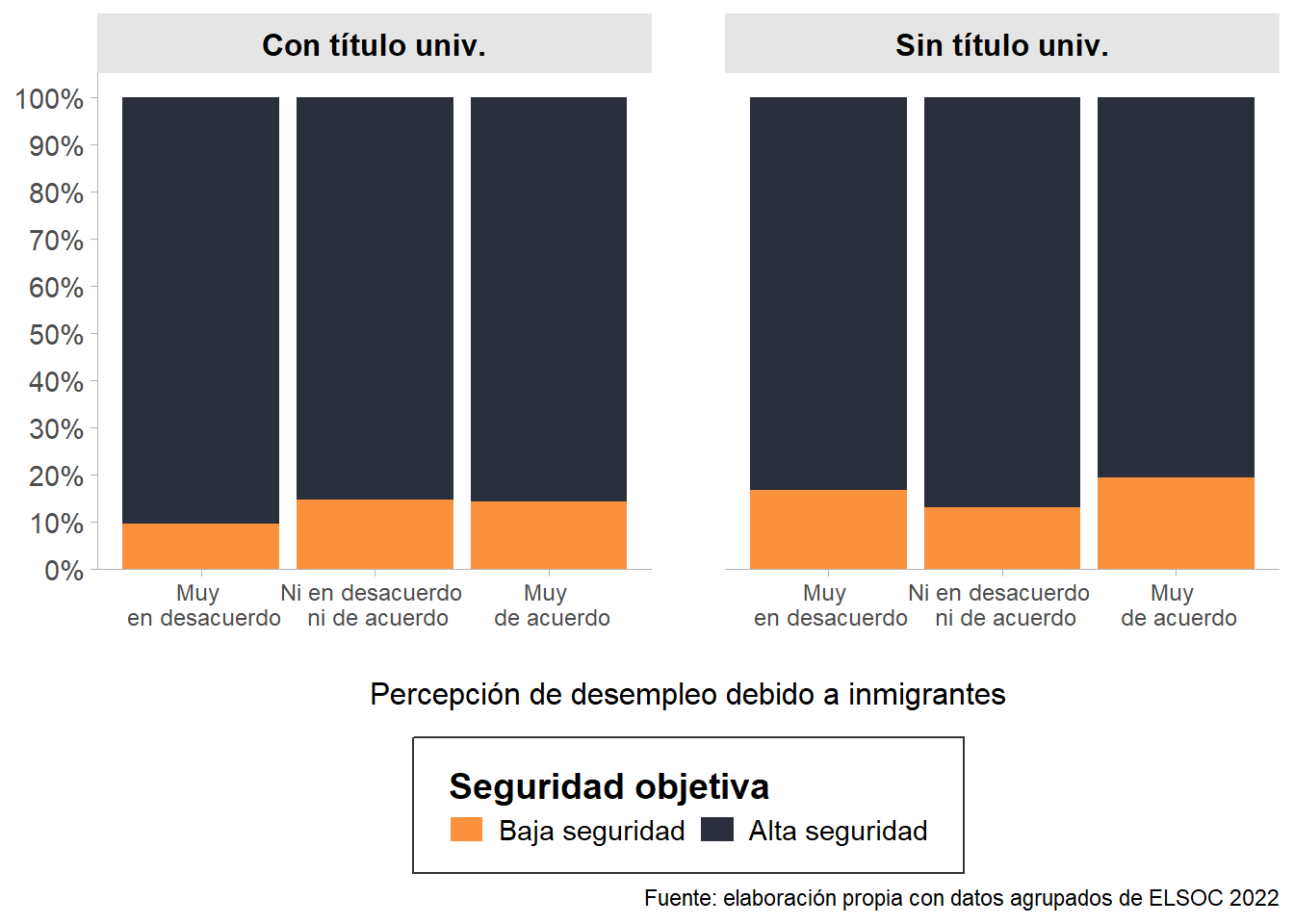
La Figure 8 compara los cruces entre la percepción de desempleo debido a inmigrantes y seguridad objetiva por nivel educacional. En la izquierda se observan las personas con título universitario, donde las mayores proporciones de quienes tienen una baja sensación de seguridad se concentran en las categorías neutra y “Muy de acuerdo”. A la derecha, se visualizan las personas sin título universitario, y aquí se puede encontrar un patrón distinto. Los sujetos sin haber terminado la educación terciaria tienden a responder en mayor medida de manera polarizada. Esto se refleja en que las categorías “Muy en desacuerdo” y “Muy de acuerdo”, son las que tienen las distribuciones más altas respecto a quienes perciben poca seguridad.
Migración y seguridad en el tiempo
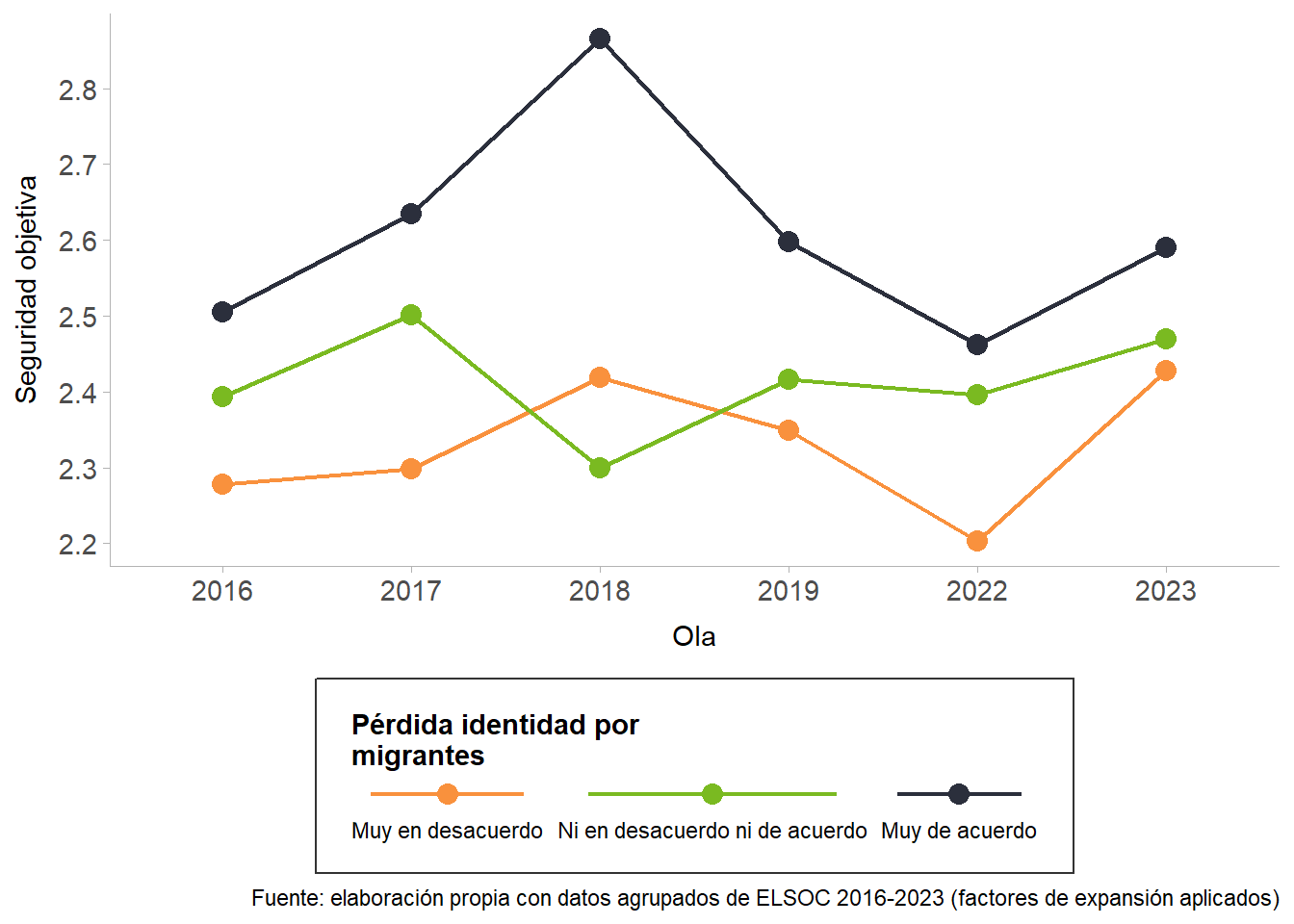
La Figure 9 muestra la evolución de la subdimensión de seguridad objetiva según el grado de acuerdo con la afirmación de que Chile está perdiendo su identidad nacional debido a la llegada de migrantes, entre 2016 y 2023. En términos generales, la seguridad objetiva es consistentemente más alta entre quienes están muy de acuerdo con la idea de pérdida de identidad, mientras que alcanza niveles más bajos entre quienes están muy en desacuerdo. El año 2018 registra el valor más alto de esta subdimensión para todos los grupos, con la excepción de quienes declaran estar ni de acuerdo ni en desacuerdo, quienes muestran un descenso en comparación con 2017.
Posteriormente, se observa una caída generalizada en los niveles de seguridad objetiva, especialmente notoria en 2022. Sin embargo, entre 2022 y 2023 emerge un repunte, más marcado en el grupo que está muy de acuerdo con la pérdida de identidad, y más moderado en quienes están muy en desacuerdo. Esto sugiere que las percepciones de seguridad objetiva se articulan en estrecha relación con las creencias sobre la migración y su efecto en la identidad nacional, y que las oscilaciones en el tiempo no afectan a todos los grupos de la misma manera. Si bien las tendencias fluctúan a lo largo del período —con un máximo en 2018, un descenso en 2022 y un repunte en 2023—, lo notable es la consistencia en la brecha entre grupos: en todos los años, quienes perciben mayor pérdida de identidad reportan mayor seguridad objetiva, lo que sugiere un patrón estable en el tiempo más allá de coyunturas específicas.
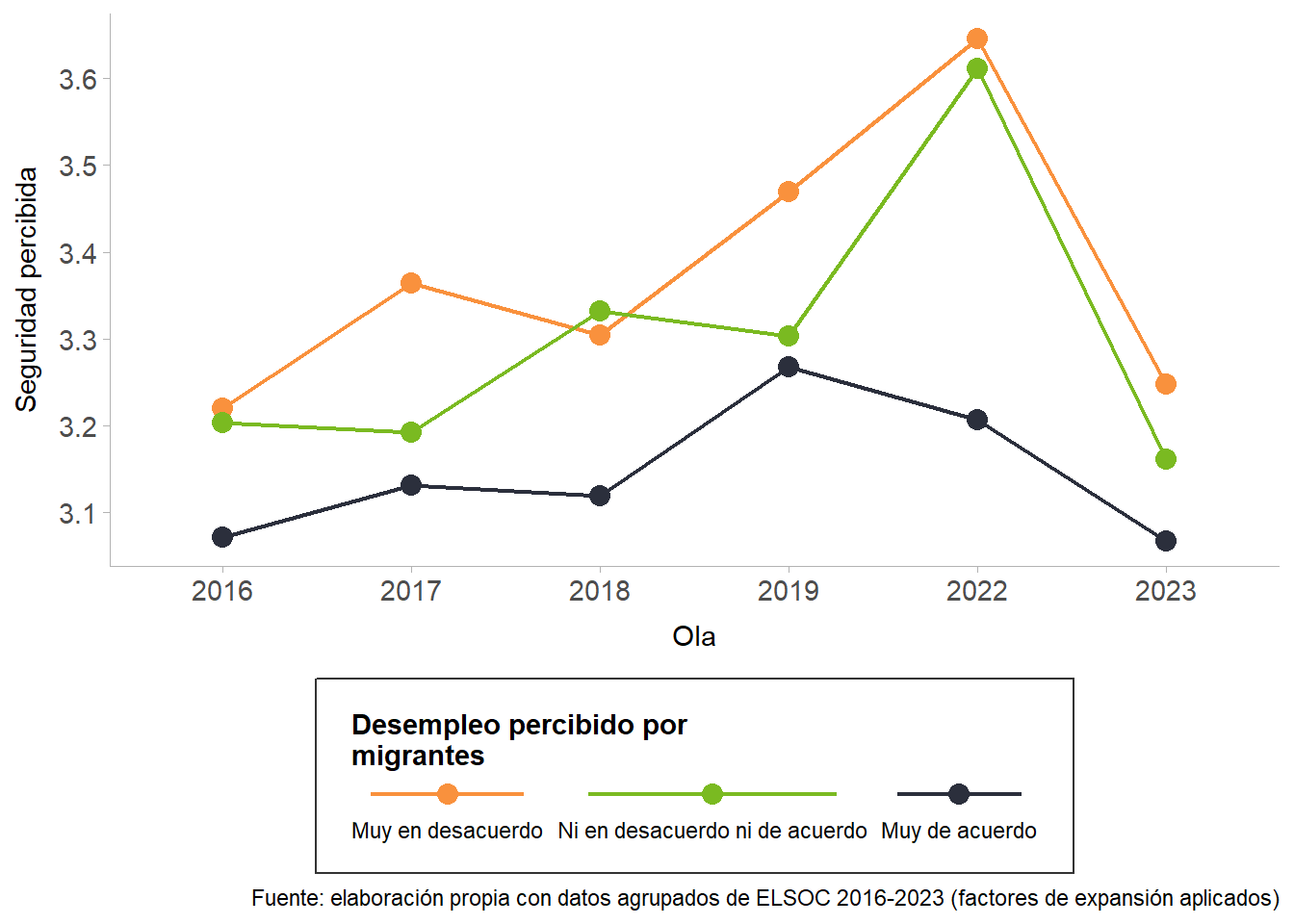
Respecto a la percepción de seguridad pública, la Figure 10 muestra su evolución entre 2016 y 2023 en relación con el grado de acuerdo respecto a que Chile pierde identidad nacional por la llegada de migrantes. En términos generales, se observa una tendencia a la baja en la percepción de seguridad durante el período analizado, especialmente marcada entre 2019 y 2023, lo que coincide con hallazgos de otros estudios recientes.
Dentro de esta trayectoria, los resultados revelan diferencias sistemáticas entre los grupos. Quienes están muy de acuerdo con la idea de pérdida de identidad presentan de manera consistente los niveles más bajos de seguridad percibida, sin mostrar variaciones que reviertan este patrón en ningún año de la serie. En contraste, quienes están muy en desacuerdo registran los valores más altos, aunque también experimentan una caída abrupta entre 2022 y 2023. Por su parte, quienes se ubican en una posición intermedia —ni de acuerdo ni en desacuerdo— muestran una evolución similar a la de los grupos en desacuerdo, con niveles relativamente altos hasta 2019, una disminución marcada a partir de 2022 y una posición intermedia entre los otros dos grupos en la comparación final de 2023.
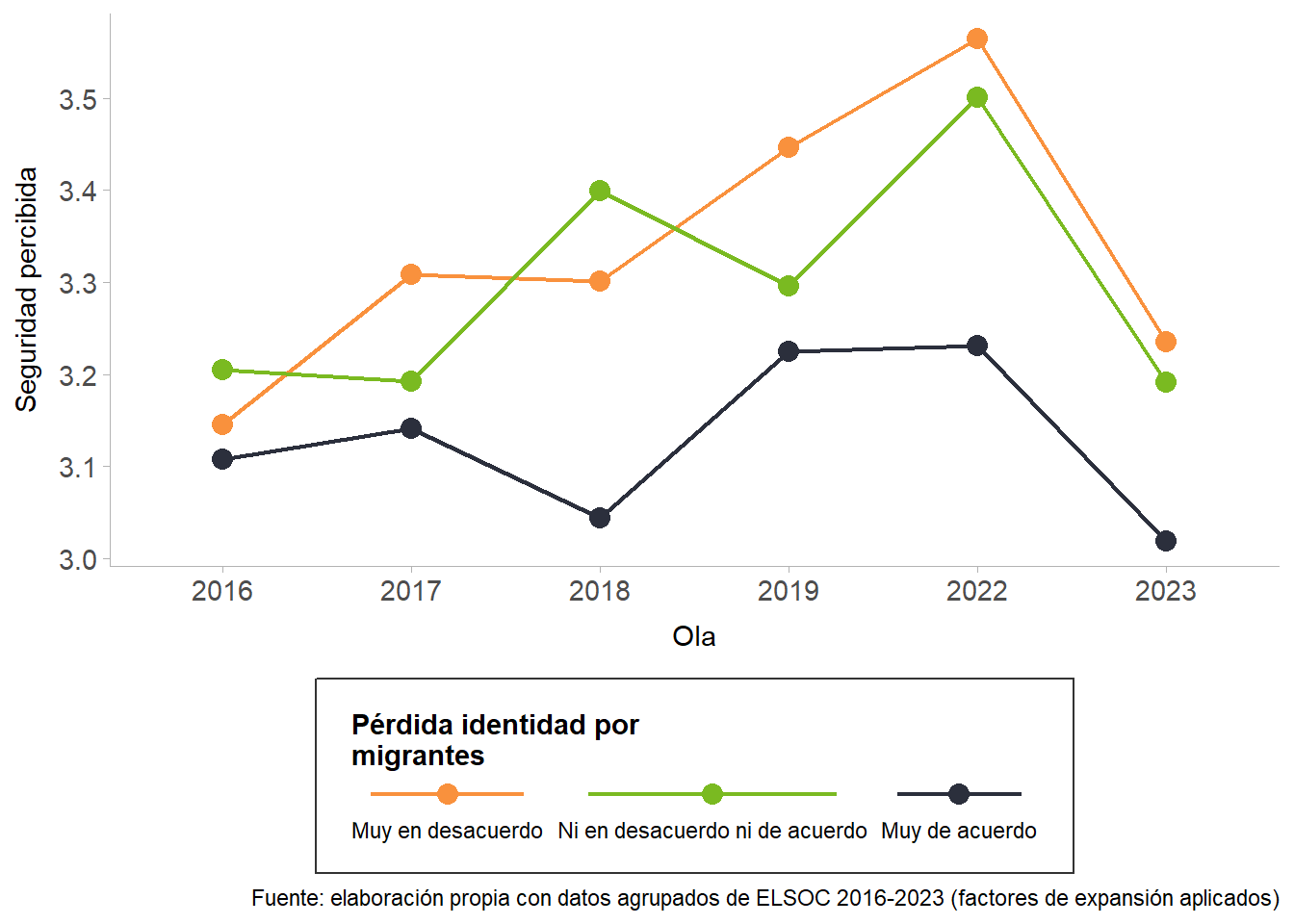
La Figure 11 muestra la evolución de la percepción de seguridad pública entre 2016 y 2023, diferenciada según el grado de acuerdo con la afirmación de que la llegada de migrantes aumenta el desempleo. Al igual que en la figura anterior, se observa una tendencia decreciente en la seguridad percibida, con una baja especialmente pronunciada entre 2019 y 2023.
En todos los años de la serie, quienes se declaran muy de acuerdo con la idea de que la migración incrementa el desempleo reportan los niveles más bajos de seguridad pública, mientras que los que están muy en desacuerdo muestran los niveles más altos. El grupo intermedio —quienes señalan estar ni de acuerdo ni en desacuerdo— se ubica de forma constante entre ambas posiciones, con una trayectoria descendente que se intensifica en los últimos años. Estos resultados sugieren que las concepciones sobre la migración, en este caso en la potencial amenaza que representa para el acceso al trabajo, se asocia con una visión más crítica o deteriorada de la seguridad pública.
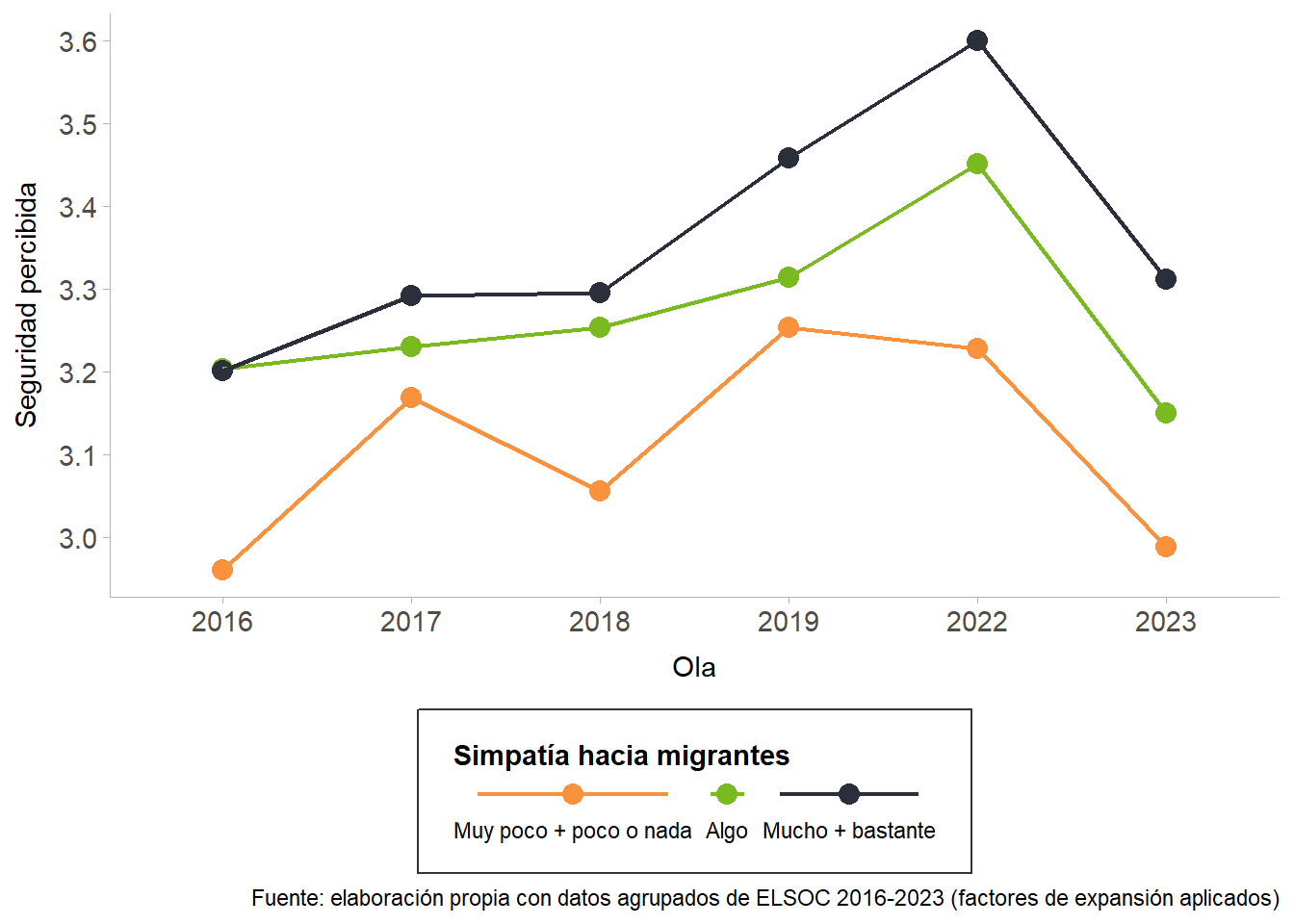
De acuerdo con la Figure 12, que muestra la evolución de la relación entre percepción de seguridad pública y grado de simpatía hacia los migrantes entre 2016 y 2023, se observa que la seguridad percibida es consistentemente más baja entre quienes expresan poca o ninguna simpatía por la población migrante. Esta brecha se acentúa desde 2019 en adelante, cuando la percepción de inseguridad en este grupo contrasta con la trayectoria ascendente que mostraban, hasta 2022, quienes dicen simpatizar algo o mucho con los migrantes. No obstante, a partir de 2022 la tendencia se revierte: todos los grupos reportan un descenso en su sensación de seguridad, aunque con intensidades distintas. Aun así, en el último año analizado se mantiene la jerarquía relativa: la percepción de seguridad es mayor entre quienes simpatizan mucho con los migrantes, seguida por quienes simpatizan algo, y alcanza sus niveles más bajos en el grupo con menor simpatía. En contraste con el caso de la pérdida de identidad, en esta dimensión las diferencias entre grupos se amplían con el tiempo, pues quienes simpatizan más con los migrantes no solo mantienen una mayor sensación de seguridad, sino que además la incrementan hasta 2022. El descenso en 2023, común a todos los grupos, sugiere la incidencia de factores coyunturales que interrumpieron esa tendencia.